
Riksrevisjonens erfaringer med datakvalitet, skjønn og algoritmer
I møte med kunstig intelligens (KI) får revisors skjønn og vurderingsevne fornyet betydning. Hvordan sikrer vi at analyser og algoritmer faktisk er pålitelige, og hvordan bygger vi nødvendig kompetanse og infrastruktur for å bruke KI på en ansvarlig måte? I denne artikkelen ser vi nærmere på hvordan Riksrevisjonen kombinerer datakvalitet, profesjonell skepsis og tverrfaglig samarbeid i praksis.
Seniorrådgiver, Riksrevisjonen

Avdelingsdirektør, Riksrevisjonen

Data science som fundament i revisjonen

For å få et helhetlig bilde av virksomhetens organisering og bruk av IT, må revisor kjenne til hvordan IT-funksjonen er strukturert og hvilken rolle den spiller i måloppnåelsen. Dette gjelder ikke bare IT-løsninger for finansiell rapportering, men også hvordan IT understøtter drift og strategi.
Riksrevisjonen har siden 2019 hatt en egen enhet for data science som samarbeider med data engineers, revisorer og IT-revisorer. Dette samarbeidet har gjort det mulig å sentralisere håndteringen av regnskaps-, faktura- og lønnsdata fra alle statlige virksomheter som bruker Direktoratet for forvaltning og økonomistyring (DFØ) som regnskapsfører, og har resultert i betydelige effektiviseringsgevinster. I tillegg har vi utviklet flere applikasjoner for semiautomatiserte analyser, eksempelvis for fakturahåndtering.
Den sentraliserte datahåndteringen, kombinert med egenutviklede applikasjoner som leverer tilrettelagte data og analyseverktøy, har frigjort tid for revisorene til risikovurdering og faglig skjønnsutøvelse. Samtidig har vi redusert risikoen for manuelle feil i håndteringen av data. Tilnærmingen har også gjort det mulig å analysere hele populasjoner, blant annet i purchase-to-pay (P2P)-prosedyrer.
Så langt har dette arbeidet i hovedsak vært basert på tradisjonell databaseteknologi og utvikling av spesialtilpassede applikasjoner. Typiske løsninger med bruk av SQL og OLAP-kuber backend med presentasjon i Excel eller Power BI, eventuelt med R Shiny-applikasjoner som frontend for mer avanserte analyser. Det er viktig å understreke at kunstig intelligens ikke vil erstatte disse metodene, i alle fall ikke på kort sikt. Mer tradisjonelle data science-tilnærminger vil fortsatt være nødvendige og nyttige, ettersom KI slett ikke er egnet til å løse alle problemstillinger.
Tverrfaglighet som suksessfaktor
Vår erfaring er at de beste resultatene i arbeidet med dataanalyser og KI kommer når teamene er tverrfaglig sammensatt: Når revisorer, IT-revisorer, data scientists og utviklere løser oppgavene sammen – både teknisk og faglig. Revisorene bidrar med innsikt og forståelse av virksomhetene, prosessene og dataene vi reviderer. Teknologene utvikler verktøy og metoder. Deretter må resultatene oversettes til revisjonsfaglige vurderinger og formidles på en måte som er forståelig også for ikke-tekniske mottakere.
IT-revisorene har hatt en særlig viktig rolle. Fordi de forstår både systemene og revisjonen. Eksempelvis når data scientists har oppdaget uventede posteringer i data fra en virksomhet, har IT-revisorene ofte kunnet forklare hvordan de kan oppstå – og i noen tilfeller avdekket systemsvakheter som ikke en gang var kjent for virksomheten selv.
Dette illustrerer at vi står i en utvikling mot en mer datadrevet revisjonskultur. Generelle IT-kontroller og testing av kontroller forblir viktige, men dataanalysen kan avdekke forhold vi ikke trodde var mulige å oppdage. Og når vi nå utvikler KI-baserte løsninger tilpasset revisorenes behov, er det tverrfaglige samarbeidet avgjørende for å lykkes.
IT som risikofaktor – hvorfor revisor må forstå mer enn regnskapssystemet
I henhold til ISA 315 (Identifisering og vurdering av risikoene for vesentlig feilinformasjon) skal revisor gjennomføre risikovurderingshandlinger for å opparbeide seg forståelse av enhetens informasjonssystemer og kommunikasjon som er relevant for utarbeidelsen av regnskapet.
For å få et helhetlig bilde av virksomhetens organisering og bruk av IT, må revisor kjenne til hvordan IT-funksjonen er strukturert og hvilken rolle den spiller i måloppnåelsen. Dette gjelder ikke bare IT-løsninger for finansiell rapportering, men også hvordan IT understøtter drift og strategi. Ofte handler dette om å vurdere IT-omgivelsenes kompleksitet og betydning.
Revisor vurderer hvor kritisk et velfungerende IT-miljø er for virksomheten. Dette forutsetter innsikt i IT-styring og det overordnede kontrollmiljøet. Endringer i IT-miljøet, som nye systemer, integrasjoner eller organisatoriske omlegginger, kan introdusere ny risiko og gjøre tidligere vurderinger utdaterte. Revisor må derfor følge med på hvordan IT inngår i virksomhetens strategiske beslutninger og risikostyring, og fortløpende vurdere hvordan endringer påvirker revisjonsrisikoen.
Bruk av IT gir betydelige gevinster, men innebærer også risiko. Komplekse IT-miljøer, automatiserte prosesser og høy grad av avhengighet kan øke sårbarheten for feil – enten applikasjoner som behandler data feil, benytter feil data, eller begge deler. IT-risikoene er ofte tett integrert i den daglige driften, noe som gjør det relevant for revisor å stille spørsmålet:
Når foreligger det ikke risiko ved bruk av IT?
Eksempler på risikoer er manglende fullstendighet, integritet og tilgjengelighet av data. For å håndtere dette vurderer revisor om virksomhetens generelle IT-kontroller er hensiktsmessig utformet og fungerer effektivt.
Bruken av kunstig intelligens (KI) aktualiserer disse problemstillingene. Innføring av KI innebærer som regel ny programvare, maskinvare eller begge deler, og bidrar til et mer komplekst IT-miljø. KI er i bunn og grunn behandling og produksjon av informasjon i IT-systemer, men generative språkmodeller representerer en særlig utfordring: De bygger på sannsynlighetsberegninger, ikke klare regler, og kan derfor produsere informasjon som er feil eller misvisende. Skjevheter i treningsgrunnlaget eller svakheter i modellutformingen kan føre til systematiske feil.
KI introduserer dermed ikke helt nye risikotyper, men forsterker og kompliserer eksisterende – særlig knyttet til fullstendighet, integritet og forklarbarhet av data. For revisor innebærer dette at vurderingen av virksomhetens IT-kontroller blir enda mer kritisk, og at påliteligheten av regnskapsinformasjon ikke kan tas for gitt når den bygger på slike modeller.
Datakvalitet ved bruk av KI – formålet avgjør vurderingsnivået
IT-systemene er selve motoren i virksomhetens evne til å produsere og håndtere finansiell informasjon. For revisor er det derfor avgjørende å ha oversikt over hvor dataene kommer fra, hvordan de flyter gjennom systemene og hvordan kontrollene underveis sikrer fullstendighet og nøyaktighet.
Vurderingen av datakvalitet – herunder behovet for å teste pålitelighet (fullstendighet og nøyaktighet) – må alltid ta utgangspunkt i formålet med databruken. Dersom KI brukes til å skaffe revisjonsbevis, for eksempel ved å identifisere avvikende transaksjoner («anomaly detection») for å avdekke misligheter, er det kritisk at dataene er pålitelige. I andre sammenhenger, som ved trening av KI-modeller til å klassifisere transaksjoner som gyldige eller ugyldige, kan det være viktigere at datasettet er variert og representativt enn at alle data er fullstendige og feilfrie.
Et nyttig kontrollspørsmål for revisor er derfor:
«Hva er formålet med databruken – og hvilke krav til datakvalitet følger av dette?»
Selv de mest avanserte analysene vil gi misvisende resultater dersom de bygger på upålitelige data. Det er derfor ikke teknologien i seg selv som avgjør kvaliteten på revisjonen, men revisors forståelse av datakilden, IT-miljøet, de relevante kontrollene og formålet med teknologibruken.
Dette gjelder også informasjon produsert av enheten (IPE) som benyttes som revisjonsbevis av revisor. For å kunne stole på slik informasjon må revisor forstå både systembaserte og manuelle prosesser som påvirker dataenes integritet. Det innebærer å vurdere hvilke kontroller som sikrer at informasjonen er fullstendig, nøyaktig og relevant – enten den hentes ut via rapporter, genereres av automatiserte verktøy eller brukes i videre analyser.
Revisjonsstandardene oppdateres – teknologi inn, styrking av skjønn
IAASB (International Auditing and Assurance Standards Board) reviderer nå ISA 500 (revisjonsbevis), sammen med ISA 330 (revisors håndtering av anslåtte risikoer) og ISA 520 (analytiske handlinger)*Audit Evidence and Risk Response | IAASB, for å gjøre standardene mer relevante i en digital og datadrevet kontekst. Et sentralt mål med oppdateringene er å styrke anvendelsen av profesjonelt skjønn og profesjonell skepsis, særlig ved bruk av teknologiske verktøy, samtidig som standardene legger til rette for økt bruk av teknologi i revisjonen.
IAASB ønsker å senke terskelen for teknologibruk ved å gi veiledning og tilpasse standardene til den teknologiske utviklingen. Teknologi løftes frem som en nødvendig og integrert del av revisjonsprosessen, ikke et tillegg. Det gis tydelig støtte til bruk av automatiserte verktøy og teknikker (ATT)*Automatiserte verktøy og teknologiske løsninger i revisjon | Revisjon og Regnskap, dataanalyse og kontinuerlig revisjon.
Også i utkastene til oppdatert ISA 240 (revisors plikter ved vurdering av misligheter)*Fraud | IAASB fremheves dataanalyse som et sentralt verktøy for å identifisere uvanlige transaksjoner og avvik. Revisorer oppfordres til å utvikle teknologiforståelse som muliggjør bruk av slike metoder innenfor en risikobasert revisjonstilnærming.
I lys av standardutviklingen og den teknologiske fremmarsjen har Riksrevisjonen satt i gang flere initiativ for å utforske hvordan vi kan bruke slike verktøy i praksis – uten at det går på bekostning av revisors skjønn. Dette inkluderer opprettelsen av et tverrfaglig KI-nettverk, beskrevet senere i artikkelen.
Når maskiner og teknologi overtar stadig mer av arbeidsoppgavene, både innen revisjon og økonomiforvaltning, blir profesjonelt skjønn og skepsis enda viktigere. Med generativ KI blir det stadig vanskeligere å vite hvilken informasjon man kan stole på; mye av det som presenteres, må vurderes kritisk før det kan tas for gitt.
Selv med økt teknologibruk*Kunstig intelligens i revisors hverdag | Revisjon og Regnskap forblir profesjonell skepsis og revisors skjønn grunnleggende. Avansert dataanalyse kan styrke risikoforståelsen og bidra til bedre prioritering, men analysene må alltid vurderes kritisk. Revisor må ha innsikt i både datagrunnlaget og verktøyenes begrensninger, og deretter vurdere om revisjonsbeviset samlet sett er tilstrekkelig og hensiktsmessig.
Kritisk tenkning og refleksjon forblir avgjørende for revisjonskvaliteten og for å stille de riktige spørsmålene. Den teknologiske utviklingen utfordrer etablerte praksiser, men gir også revisjonsfaget nye verktøy for å identifisere risiko, hente bevis og skape verdi. For å møte endringene må revisor forstå systemer, data og kontrollmiljø – og være villig til å samarbeide tverrfaglig der det trengs. Teknologi endrer ikke revisjonens kjerne, men skjerper kravene til innsikt, skjønn og kritisk tenkning.
På vei mot ansvarlig KI – gjennom prøving og feiling
Riksrevisjonens utgangspunkt er klart: Vi skal «bruke teknologi så langt det er mulig og ta aktivt i bruk kunstig intelligens på en ansvarlig måte – både i revisjonsarbeidet og i utviklingen av organisasjonen». Vår vurdering er at utstrakt bruk av KI kan gi betydelige effektiviseringsgevinster og samtidig bidra til bedre revisjonskvalitet.
Samtidig vil ikke KI gjøre mer «klassiske» verktøy og analyseteknikker overflødige. Mange oppgaver vil i overskuelig fremtid fortsatt løses best med tradisjonelle metoder, eksempelvis SQL. Bruk av KI må derfor ses som en del av et bredere teknologibilde.
Å avstå fra å benytte KI er imidlertid ikke et reelt alternativ. Det må likevel skje på en måte som både ivaretar tilliten til Riksrevisjonen og gir reelle gevinster. For å styre utviklingen har vi etablert en egen KI-strategi. Den fastslår blant annet at vi skal
utvikle og ta i bruk KI-baserte verktøy
sikre tilgang til nødvendig infrastruktur og spisskompetanse for trygg bruk i stor skala
være et ledende miljø for revisjon av KI innen 2027
Eksempel: Anomaly detection
Ett av prosjektene våre er en løsning for «anomaly detection», bygget på nyere metoder som isolation forest og autoencoders. Slike modeller er godt egnet når vi ikke har treningsdata som definerer hva som er «avvikende transaksjoner» i revisjonssammenheng. Som kjent finnes det sjelden en fasit – og i noen tilfeller kan det være enkelt å finne «nåla i en høystakk», men det blir utfordrende når vi ikke vet hvordan «nåla» ser ut. Derfor må vi ofte støtte oss på ikke-veiledede, datadrevne modeller som flagger avvik basert på egenskaper i datamaterialet. Ulempen er at dette kan gi mange falske positiver, men vi mener utviklingen nå gjør det mulig å bygge et nyttig «state-of-the-art» verktøy for å analysere avvikende transaksjoner.
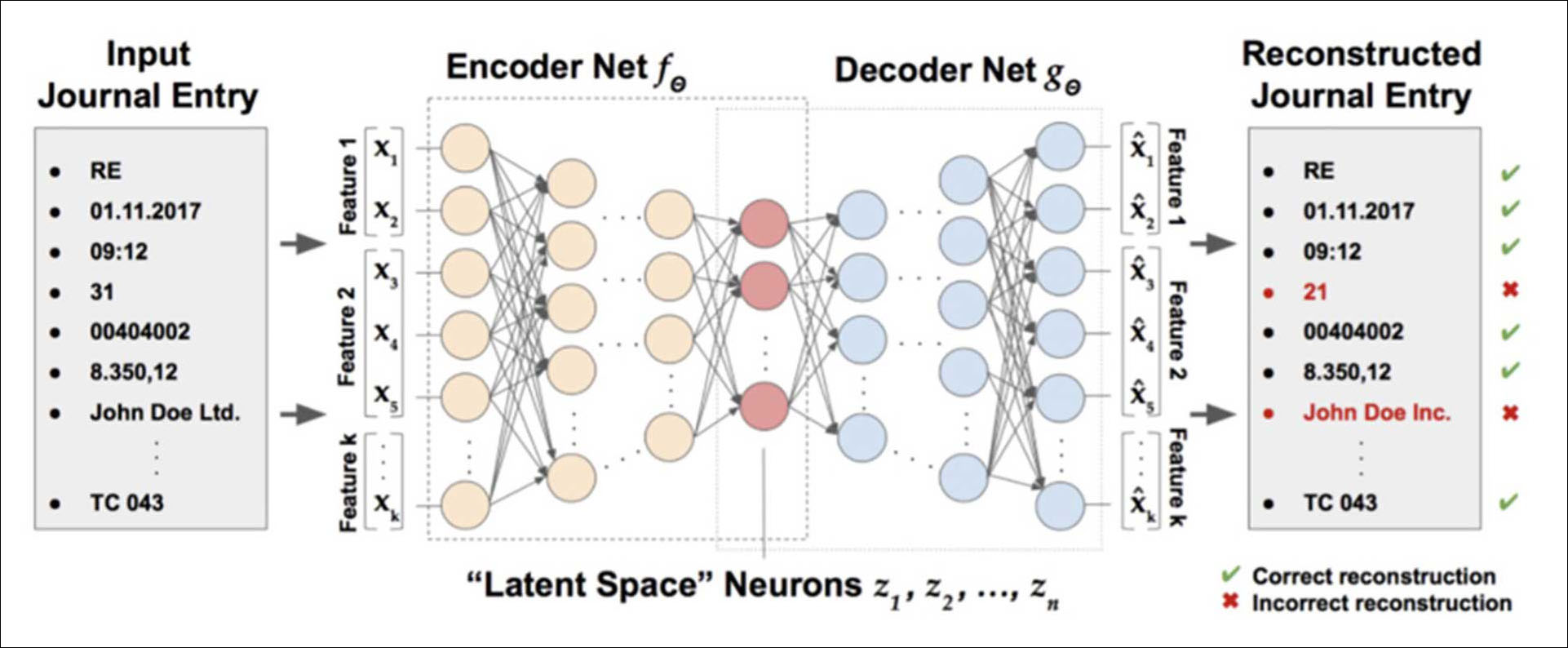
Eksempel på autoencoder brukt til rekonstruksjon av transaksjonsdata (kilde: https://github.com/GitiHubi/deepAI?tab=readme-ov-file og figur publisert for åpen bruk under GPL-3.0 lisens).
Om autoencoders for anomaly detection:
Autoencoders er en dyplæringsmodell der man først trener en modell på et helt ordinært sett av transaksjoner. Deretter «koder» (encoding) man eksempelvis alle de aktuelle føringene i hovedbok til en numerisk representasjon. Så får man modellen til å «dekode» (decoding) representasjonen tilbake til den originale verdien. Resultater der det er stort avvik mellom den originale og den rekonstruerte verdien, er således å regne som et avvik.
Se https://arxiv.org/abs/1709.05254
Når en ny transaksjon ligner på det modellen har sett før, klarer den å gjenskape den nesten helt likt. Men dersom transaksjonen skiller seg mye fra det normale, får modellen problemer med å gjenskape den. Resultatet blir da et stort avvik mellom originalen og den rekonstruerte transaksjonen – og dette kan derfor regnes som et mulig avvik.
LLM og RAG
Parallelt utforsker vi bruk av LLM-baserte løsninger. Et viktig satsingsområde er såkalte RAG-pipelines (Retrieval Augmented Generation)* For en presentasjon av RAG, se eksempelvis https://medium.com/@social_65128/the-ultimate-guide-to-understanding-advanced-retrieval-augmented-generation-methodologies-467cd05a2ecd , der en kunnskapsbase – eksempelvis revisjonsstandarder – brukes som grunnlag for modellens svar. Dette reduserer sannsynligheten for hallusinasjoner og gjør teknologien mer anvendelig i revisjon.
Vi ser også på KI-agenter som kan utføre konkrete oppgaver. Hvor langt vi kan gå her må vurderes løpende, siden agentene ofte bygger på språkmodeller som kan være upålitelige. Vi kan ikke risikere å «outsource» en oppgave til en KI-agent som leverer feil uten at vi oppdager det.
Kontroll på data krever kontroll på infrastrukturen
I Riksrevisjonen er det et grunnleggende prinsipp å ha kontroll på behandlingen av interne data. Bruk av eksterne generative KI-tjenester innebærer at dokumenter sendes til tredjepartsløsninger utenfor vår kontroll, med risiko for både tap av konfidensialitet og manglende oversikt over hvordan data lagres og brukes videre. Dette er problematisk for oss, og vi ser derfor behov for å utvikle egne KI-tjenester tilpasset våre formål. Løsningene vil dels baseres på public cloud, og dels gjennom et GPU-cluster – en samling grafikkprosessorer som sammen gir høy regnekraft, og som gjør det mulig å kjøre KI-modeller lokalt.
Valget av en kombinasjon skyldes flere forhold. For det første har bruken av amerikanske skytjenester blitt mer usikker på grunn av den politiske situasjonen. President Donald Trump har allerede avviklet deler av Data Privacy Framework (DPF)-avtalen mellom EU og USA* Se eksempelvis https://www.politico.eu/article/usa-donald-trump-privacy-watchdog-dismantle-personal-data/ , og ettersom avtalen er basert på presidentordre snarere enn lovgivning, kan den endres eller oppheves med kort varsel. Dette skaper politisk ustabilitet i rammeverket for personvern og datasikkerhet.
For det andre: Selv om maskinvare – særlig GPU-er – representerer betydelige investeringskostnader, er det ikke gitt at skytjenester vil være vesentlig rimeligere. Ønsker man eksempelvis å «fine-tune» språkmodeller for egne formål, kan leie av nødvendig regnekraft i skyen beløpe seg til titusenvis av kroner per måned.
Et GPU-cluster gir dessuten fleksibilitet ved at det også kan benyttes til andre beregningskrevende analyser, uavhengig av KI. Analyser basert på omfattende geodata er ett eksempel på dette.
Slik bygger Riksrevisjonen KI-kompetanse i praksis
For å kunne både ta i bruk KI i revisjonsarbeidet og revidere KI-løsninger, er det nødvendig å utvikle både spisskompetanse og breddekompetanse.
På spisskompetansesiden har vi inngått et partnerskap med Norwegian Open AI Lab (NAIL) ved NTNU, ett av Norges fremste forskningsmiljøer innen KI. Samarbeidet gir oss tilgang til ledende forskere og skal særlig styrke vår kompetanse på «forklarbar KI», et område med stor betydning for revisjon. Vi bygger også opp kapasitet internt ved å ansette flere data scientists med solid modell- og KI-kompetanse. I tillegg har vi tett dialog med riksrevisjonene i Tyskland, England, Brasil, Nederland og Finland – miljøer som regnes blant de mest avanserte i verden når det gjelder teknologi i revisjon. Dette samarbeidet har blant annet resultert i veiledningen Auditing Machine Learning Algorithms – A whitepaper for public auditors * Se: https://auditingalgorithms.net (Whitepaper under revidering, ny versjon forventes høst 2025)..
For å utvikle breddekompetanse har vi etablert et internt, tverrfaglig KI-nettverk. Her deltar medarbeidere fra finansiell revisjon, etterlevelsesrevisjon, forvaltningsrevisjon, HR, IT og data science. Nettverket er en arena for kompetanseheving og metodeutvikling på tvers av organisasjonen. Deltakerne skal bidra til å bygge forståelse for ulike typer KI-systemer og de tilhørende risikoene, og være ressurspersoner i revisjoner der KI inngår – enten i revisjon av virksomheten eller gjennom bruk av egne verktøy i revisjonen. Tematisk spenner arbeidet fra store språkmodeller og etiske problemstillinger til konkrete bruksområder som dokumentklassifisering og avviksanalyse. Nettverket har dermed lagt et viktig grunnlag for å utvikle metodikk, skape felles forståelse og identifisere hvor KI kan gi verdi i revisjonen.
Veien videre for KI i revisjonsarbeidet
Vi i Riksrevisjonen tror at KI vil bli en stadig viktigere del av både revisjonsobjektenes systemlandskap og vår egen verktøykasse. Samtidig er vi overbevist om at teknologien aldri kan erstatte revisors kjerneoppgaver: å utøve profesjonelt skjønn, vurdere kvaliteten på datagrunnlaget og sikre at revisjonsbevisene er tilstrekkelige og hensiktsmessige.
KI gir oss nye muligheter til å analysere store datamengder, oppdage mønstre vi ellers ikke ville sett, og effektivisere deler av revisjonsprosessen. Men teknologien innebærer også nye og skjerpede risikoer – særlig knyttet til datakvalitet, forklarbarhet og kontrollmiljø. Det stiller høyere krav til oss som revisorer: Vi må forstå systemene bedre, stille tydeligere spørsmål og samarbeide enda tettere på tvers av fagområder.
Veien videre handler derfor ikke om å velge mellom tradisjonelle metoder og KI, men om å kombinere dem på en ansvarlig måte. Med tverrfaglig kompetanse, god metodeutvikling og kritisk refleksjon kan vi sikre at KI styrker revisjonskvaliteten – og dermed også tilliten til Riksrevisjonen.
.gif)